
目標先講清楚:
透過分析Manus的文章,探討Manus的agent處理50次以上工具調用的長上下文的方式,而不會工具爆炸
Manus的目的很明確 - 省錢,因此圍繞 KV-cache 設計;
KV-cache是什麼:模型在處理文字(system prompt)時,每讀一段前綴,都會算注意力裡的 Keys / Values。把這些中間結果暫存起來,下次前綴一樣時就直接重用;可以參考大模型上下文工程之Prefix Caching技术详解,有詳細的說明。

從以上API價目表可知,快取輸出 vs 一般輸入,價差10x
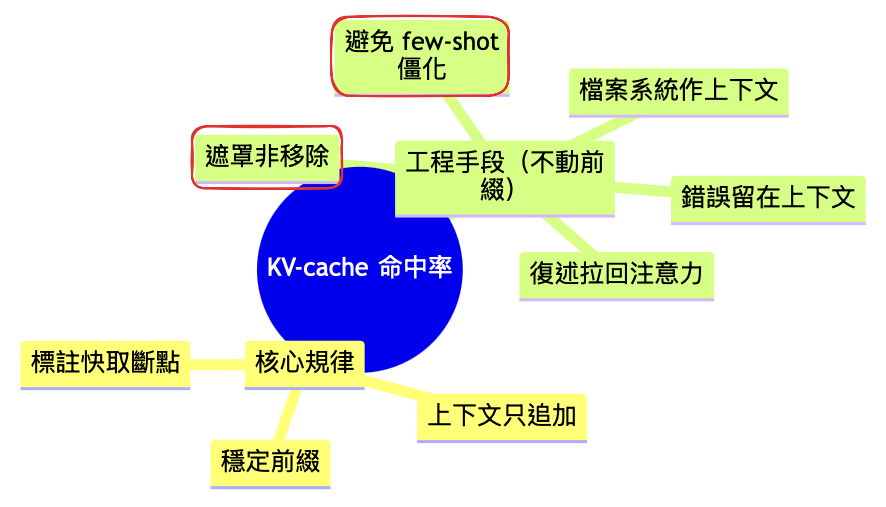
其他的方式比較好理解,但比較特別的是:遮罩非移除及避免few-shot僵化
這個技巧Anthropic也有提過類似的概念 - Day 23|Agent Design - Context - Anthropic-writing effective tools for ai agents 筆記(2/5)提到「用命名空間去劃清界線」
做法:
範例:
# 以 Hermes/ChatML 類開源模型為例,可在聊天模板上先「預填」回覆到工具呼叫區塊與名稱前綴,把選擇導向某一群(如 browser_*)。
from transformers import AutoTokenizer, AutoModelForCausalLM
tok = AutoTokenizer.from_pretrained("NousResearch/Hermes-4-14B")
mdl = AutoModelForCausalLM.from_pretrained("NousResearch/Hermes-4-14B")
messages=[{"role":"system","content":"你是…"}, {"role":"user","content":"搜尋便宜旅館"}]
prompt = tok.apply_chat_template(messages, add_generation_prompt=True) \
+ '<tool_call>{"name":"browser_' # ← 預填到名稱前綴
inputs = tok(prompt, return_tensors="pt")
out = mdl.generate(**inputs, max_new_tokens=64)
print(tok.decode(out[0], skip_special_tokens=False))
OpenAI-enum和langchain-tool_choice也是類似的用法:
# Open AI SDK
schema = {
"name":"Action",
"schema":{
"type":"object",
"properties":{
"tool":{"type":"string","enum":["browser_search","browser_open"]}, # ← 子集合
"args":{"type":"object"}
},
"required":["tool","args"]
}
}
# Langchain
def call_llm(state, user_input, history):
allowed = list(ALLOWED[state]) # 遮罩集合
# 將 allowed 傳給模型的 tool_choice / logits mask
resp = llm.invoke(
system_prefix=FIXED_PREFIX, # 不變
messages=history + [user_input], # 追加式上下文
tools=FIXED_TOOLSET, # 不變(不增不刪)
tool_choice={"type":"allowed", "names":allowed}, # 僅在此狀態可見
response_format=SCHEMA_ENFORCED # 結構化輸出(可選但建議)
)
return resp
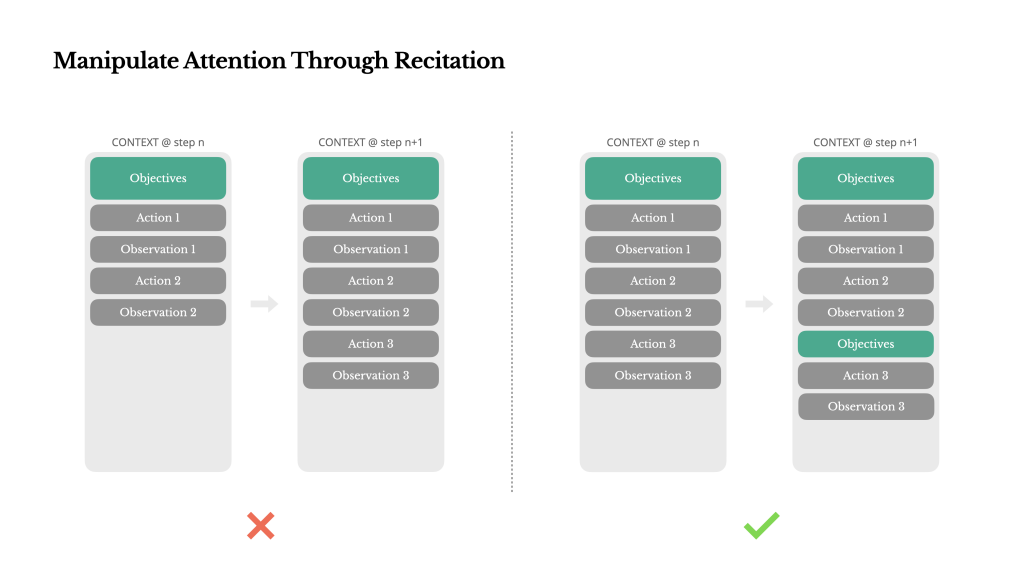
若把相同格式的 few-shot 範例或「上一份的批注」放進同一個上下文裡,模型會傾向延續最近看到的模式
做法:
範例:
# rubric 語句池(任務說明的小幅變體)
[RUBRIC_1] 重申:請避免抄回模板文字,直接輸出 JSON。
[RUBRIC_2] 注意:先判斷硬性拒絕,再綜合評分;最後只給 JSON。
[RUBRIC_3] 校準:若不確定,往「medium/weak」靠,不要高估;最終只輸出 JSON。
# Prompt組成
[CURRENT RESUME INPUT]
<貼上候選人履歷內容或抽取後的結構化欄位>
[RUBRIC - 依 seed 選擇的一句]
<插入 RUBRIC_1 或 2 或 3 之一>
會先介紹到如果想使用LLM進行評估,這個LLM或是Agent有哪些要注意的部分
1.AI代理的上下文工程:從構建Manus中學到的經驗
2.大模型上下文工程之Prefix Caching技术详解
3.Anthropic - Prompt caching
4.OpenAI - Prompt caching
5.Prefill Claude's response for greater output control

 iThome鐵人賽
iThome鐵人賽